Lead: It can be said that the correct assessment of the progress of machine learning is very subtle. After all, the goal of the learning algorithm is to generate a model that can be well generalized to invisible data. Therefore, in order to understand the reliability of current advances in machine learning, scientists at the University of California, Berkeley (UC Berkeley) and the Massachusetts Institute of Technology (MIT) designed and conducted a new reproducibility study. Its main goal is to measure the extent to which contemporary classifiers are generalized from the same distribution into new, truly invisible data.
It can be said that machine learning is currently dominated by experimental research institutes focused on improving some key tasks. However, the impressive accuracy of the best-performing models is questionable because it has been many years since these models were selected with the same set of tests. In order to understand the danger of overfitting, we measured the accuracy of the CIFAR-10 classifier by creating a new test set of truly invisible images. Although we ensured that the new test set was as close to the original data distribution as possible, we found that the accuracy of most of the deep learning models dropped significantly (4 to 10%). However, newer models with higher original accuracy show smaller declines and better overall performance, suggesting that this decrease may not be due to fitness-based overfitting. Instead, we view our results as evidence that the current accuracy is fragile and vulnerable to small natural changes in the distribution of data.
In the past five years, machine learning has become a decisive field of experimentation. Driven by a large amount of research in the area of ​​deep learning, most of the published papers have adopted a paradigm. The main reason why a new learning technology emerges is its improved performance on several key benchmarks. At the same time, there is almost no explanation as to why the proposed technology now has more reliable improvements than previous studies. Instead, our sense of progress depends largely on a few standard benchmarks, such as CIFAR-10, ImageNet, or MuJoCo. This raises a key issue:
How reliable is our current progress in machine learning?
It can be said that the correct assessment of the progress of machine learning is very subtle. After all, the goal of the learning algorithm is to generate a model that can be well generalized to invisible data. Since we usually do not have access to the real data distribution, we instead evaluate the performance of a model on a separate test set. As long as we do not use test sets to select our model, this is indeed a principled evaluation protocol.

Figure 1: Class-balanced random extraction results from new and original test sets.
Unfortunately, we usually have limited access to new data in the same distribution. Nowadays, it is generally accepted that the same test set is reused multiple times throughout the algorithm and model design process. Examples of this approach are very rich, including the adjustment of hyperparameters (layers, etc.) in a single release product, and architectural builds on the research of various published products of other researchers. Although the comparison of the new model with the previous results is a natural desire, it is clear that the current research method undermines the key assumption that the classifier is independent of the test set. This mismatch poses a significant risk because the research community can easily design models. However, these models can only perform well on specific test sets and cannot actually be generalized to new data.
Therefore, in order to understand the reliability of the current machine learning progress, we designed and conducted a new reproducibility study. Its main goal is to measure how far contemporary classifiers are generalized from the same distribution to new, truly invisible data. We focus on the standard CIFAR-10 data set because its transparency creation process makes it particularly suitable for this task. Moreover, CIFAR-10 has now become a hot topic in the past 10 years. Due to the competitive nature of this process, this is a good test case to investigate whether adaptability leads to overfitting.
Overfitting
Does our experiment show overfitting? This can be said to be the main problem in explaining our results. To be precise, we first define two concepts of overfitting:
• Training set overfitting: One way to quantify overfitting is to determine the difference between training accuracy and test accuracy. It should be noted that the deep neural network in our experiments usually achieve 100% training accuracy. So this concept of overfitting already appears on existing datasets.
• Test Set Overfitting: Another concept of overfitting is the gap between test accuracy and the accuracy of the underlying data distribution. By fitting the model design choices to the test set, we are concerned that we implicitly fit the model to the test set. Then, test accuracy as an accurate measure of performance on truly invisible data will lose its effectiveness.
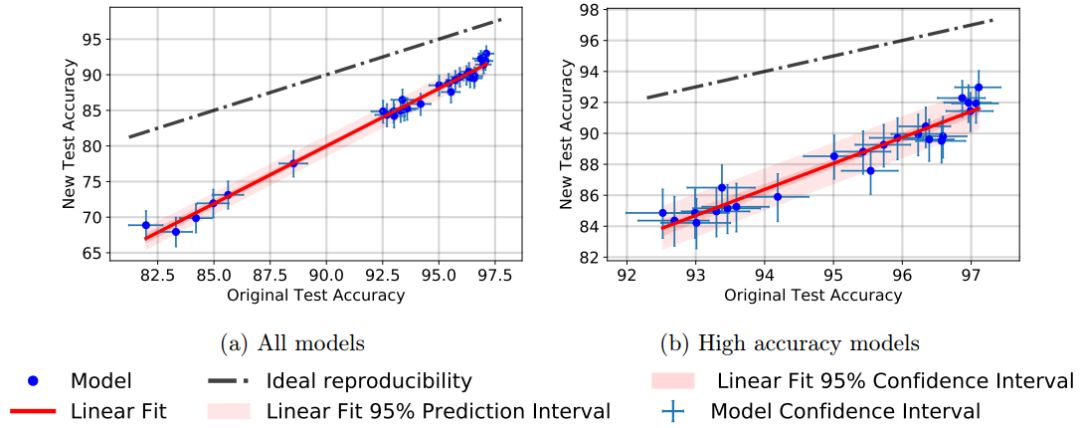
Figure 2: Model Accuracy of New Test Set vs. Model Accuracy of Original Test Set
Since the overall goal of machine learning is to generalize to invisible data, we believe that the second concept is more important for adaptive overfitting of the test set. Surprisingly, our results show no signs of overfitting on CIFAR-10. Despite years of competitive self-adaptation on this data set, the data actually held did not stagnate. In fact, in our new test set, the best-performing models have more advantages than more established baselines. Although this trend is contrary to what is shown by the overfitting of fitness. Although a conclusive picture requires further replication experiments, we believe that our result is to support a competition-based approach to improve the accuracy score.
We note that we can read this analysis by reading the analysis of the Ladder algorithm of Blum and Hardt. In fact, they show that by adding minor modifications to standard machine learning competitions, it is possible to avoid overfitting that is achieved through positive adaptation. Our results show that even without these modifications, model adjustments based on test errors do not lead to overfitting of the standard dataset.
Distribution shift (distribution shift)
Although our results do not support the hypothesis of adaptation-based overfitting, significant differences between the original and new precision scores still need to be explained. We believe this difference is the result of a small distribution of displacements between the original CIFAR-10 data set and our new test set. Although we tried hard to duplicate the creation process of CIFAR-10, this gap was large and affected all models, and this happened. In general, we will study the distribution of displacements for specific changes in the data generation process (for example, changes in lighting conditions) or worst-case attacks in adversarial environments. Our experiments were more gentle and did not bring these challenges. Despite this, the accuracy of all models decreased by 4-15% and the relative increase in error rate was as much as 3 times. This shows that the current CIFAR-10 classifier is difficult to generalize into the natural change of image data.
Future research
Specific future experiments should explore whether competing methods are also resilient to overfitting on other datasets (eg ImageNet) and other tasks (eg language modeling). An important aspect here is to ensure that the data distribution of the new test set is as close to the original data set as possible. In addition, we should understand what type of naturally occurring distribution changes are challenging for image classifiers.
More broadly, we view our results as motivation for a more comprehensive assessment of machine learning research. At present, the main paradigm is to propose a new algorithm and evaluate its performance on existing data. Unfortunately, the extent to which these improvements can be widely applied is often poorly understood. In order to truly understand the generalization problem, more research should gather insightful new data and evaluate the performance of existing algorithms on these data. Since we now have a large number of pre-registered classifiers in the open source code base, such research will comply with accepted statistically valid research standards. It is important to pay attention to distinguishing the current reproducibility efforts in machine learning, which are generally focused on the reproducibility of the calculations, ie running the released code on the same test data. In contrast, generalization experiments such as ours focus on statistical reproducibility by evaluating the classifier's performance on real new data, similar to recruiting new participants for medical or psychological reproducibility experiments.
This series high power density programmable DC electronic load provides three voltage ranges 200V DC Electronic Load/600V DC Electronic Load /1200V DC Electronic Load. Supports CV, CC, CR and CP these 4 basic operating modes, as well as CV+CC, CV+CR, CR+CC these 3 complex operating modes. Full protection includings OCP, OPP, OTP, over voltage and reverse alarm. Support external control and monitor mode, the 0 to 10V input or output signal represent 0 to full range voltage or current. Provide OCP test, OPP test and Short circuit simulation to effectively solve the application demands for power and automated testing. Built-in RS232, RS485 and USB communication interfaces, LAN&GPIB communication card is optional. Two or more loads can be connected in master-slave parallel mode to provide more power or current capacity,which can make DC Electronic Load System in 200V DC Electronic Load System,600V DC Electronic Load System,1200V DC Electronic Load System . This series DC load can be applied to battery discharge, DC charging station and power electronics and other electronics products.
Speical features as below:
â— Flippable front panel and color touch screen allow convenient access and operation
â— Provides four kinds of basic working mode such as CV/CC/CR/CP, and CV+CC/CV+CR/CR+CC complex operating modes
â— Adjustable current slew rate, adjustable CV loop speed
â— Ultra high precision voltage & current measurement
â— OCP/OPP testing function
â— 50kHz high-speed CC/CR dynamic mode
â— 500kHz high-speed voltage and current sampling rate
â— Timing & discharging measurement for batteries
â— Short circuit test mode
â— Auto mode function provides an easy way to do complicated test
â— Dynamic frequency sweep function for determining worst case voltage peaks*
â— Non linear load mode function makes the simulated loading current more realistic*
â— Supports external analog control function*
â— V-monitor/I-monitor
â— LED load simulation function
â— Full protection: OCP, OPP, OTP, over voltage and reverse alarm
â— Up to 20 units master/slave parallel control
â— Front panel USB interface supports data import and export
â— SCPI language and standard rack size make it ideal for ATE System integration
â— Smart fan control with lower noise and better for environment
â— Multi versions to meet the cost performance and different applications
* Only professional Electronic Load units support these functions
DC electronic load,electronic load,DC load,ac electronic load, electronic load
APM Technologies Ltd , https://www.apmpowersupply.com