Editor's Note: To what extent is the conflict between privacy protection and security protection a technical limitation? Let's work with DeepMind data scientist and Udacity deep learning tutor Andrew Trask to implement crime detection based on Paillier encryption algorithm and word bag logic regression.
TLDR: Can monitoring only violate the privacy of criminal suspects and terrorists and avoid innocence? This article implements a prototype in Python.
Abstract: Modern criminal suspects and terrorists hide in the pattern of innocent residents, accurately mirroring the daily lives of innocent residents until the last moment they become fatal, such as a car rushing to the sidewalk, or a street The knife man. Since the immediate fatality is unlikely to be intervened by police force, law enforcement turned to surveillance to detect crime, and legislative efforts have accelerated this turn, such as the Patriot Act, the US Freedom Act, and the UK's counter-terrorism bill. These legislations have caused fierce controversy. In this article, we will explore the extent to which privacy and security tradeoffs are merely a technical limitation, a technical limitation that can be overcome by homomorphic encryption and deep learning. We also present a prototype implementation and discuss where additional technology investments can be made to make this technology more mature. I am optimistic that future crime detection tools will be stronger than today, protecting residents' privacy while providing more efficient monitoring. Potential abuse can be mitigated by modern technologies such as encrypted artificial intelligence.
If you are interested in training encrypted neural networks, you can take a look at OpenMined's PySyft library.
First, the ideal resident monitoring
Drug detectors are often used at international airports to detect drugs. If there is no drug dog, it is an expensive, time-consuming and privacy-intrusive process to detect whether a passenger carries drugs and open each bag to check the contents. However, with the drug dogs, the bags that need to be searched are only those bags that do contain drugs (in the eyes of drug dogs). The application of the drug dog also increases privacy and efficiency.

Similarly, the use of electronic smoke alarms and burglar alarms has replaced the more expensive and more privacy-invasive systems: 24x7 security guards or firefighters standing at the door.
There is almost no compromise between privacy and security in these two scenarios. This is the ideal state of monitoring. Monitoring is effective and privacy is protected:
Intrusion of privacy is only possible when dangerous/criminal activities are likely to be discovered.
The equipment is accurate and the false positive rate is low.
The person who can access the device (the police officer accompanying the drug dog and the property owner) does not attempt to fool these devices. Therefore, the working mechanism of these devices can be made public, and the protection of privacy can be known and audited.
The combination of privacy protection, accuracy, and auditability is key to achieving an ideal state of monitoring. This is very intuitive. With less than 0.001% of aircraft passengers carrying drugs, why should each bag be opened and the privacy of each passenger violated? Since there is no fire or burglary in 99.999% of the time, why should the security monitor the surveillance video of the owner's home?
Second, national security monitoring
In the two weeks I wrote this article, more than 50 people in Manchester, London, Egypt, and Afghanistan died of terrorist attacks. I pray for the victims and their families, and I hope that we can find a better way to protect people's safety. A recent survey of terrorist attacks in Westminster shows that terrorists exchange information through Whatsapp. This has sparked a heated debate about the compromise between privacy and security. The government wants to put backdoors (including unlimited read access) in applications like Whatsapp, but many people don't trust Big Brother's self-discipline to protect the privacy of WhatsApp users. In addition, the placement of the back door also makes these applications vulnerable to attack, further increasing the public's risk.
Terrorism may be the most discussed area in the compromise between privacy and security, and it is not the only area that has been discussed. Crimes such as murder have claimed the lives of thousands of people around the world. In the United States alone, there are approximately 16,000 murders per year.
Chicken and Egg Problems “Considerable†The challenges faced by the FBI and local law enforcement agencies are very similar to terrorism. The law protecting the privacy of citizens led to a chicken and egg problem, finding “reasonable reasons†(and then obtaining a search warrant) and accessing information that was “reasonableâ€. In the case of drug dogs and smoke alarms, this is no longer a problem, because crime can be detected without significant additional damage to privacy, so "reasonable reason" is no longer a restriction on public safety. factor.
Third, the role of artificial intelligence
In the ideal world, there will be a "fire alarm" device for irreversible and serious crimes such as murder and terrorist attacks. The device can protect privacy, accuracy and auditability. Fortunately, commercial entities have invested heavily in the development of such testing equipment. These inputs are not driven by protecting consumer privacy. Instead, these devices were developed to achieve large-scale inspections. Considering the development of Gmail, Gmail wants to provide spam filtering. You can invade people's privacy and manually read their mail, but creating a machine that can detect spam is faster and cheaper. Since law enforcement wants to protect the population, it is not difficult to imagine that this process is highly automated. Therefore, based on this assumption, what we really lack is the ability to convert the AI ​​agent to meet the following conditions:
Allows trusted parties to audit their privacy
Cannot be reverse engineered after deployment
The monitored person cannot know the prediction
The deployer cannot tamper with the forecast (such as chat software)
Efficient, scalable
To fully illustrate this concept, we will create a prototype. In the next section, we will use a two-layer neural network to create a base version of the detector. We will then upgrade this detector to meet the requirements listed above. This detector will be trained on the spam database, so only spam will be detected. However, it is conceivable that after training, it can detect any specific event you want to detect (eg, murder, arson, etc.). The reason I chose spam is because it's relatively easy to train, so I can demonstrate this method.
Fourth, create a spam detector
Therefore, our demonstration case will be a local law enforcement official (let us call him "Bob") hope to crack the crime of sending spam. However, Bob does not intend to read everyone's emails in person. Instead, Bob wants to detect spam, so he can apply for injunctions and search warrants and conduct further investigations. The first part of the process is to create an effective spam detector.

Enron Spam Dataset We need a lot of messages marked as "spam" and "non-spam" to let the algorithm learn to distinguish between two different messages. Fortunately, a well-known energy company has committed some crimes. These crimes are recorded in the mail, so the company's quite a lot of mail has been made public. Because many of these messages are spam, people built an Enron Spam Dataset based on these public messages. I preprocessed this dataset and generated two files:
Ham.txt Non-spam, a total of 22032.
Spam.txt spam, a total of 9000.
Each line of the file is an email. We will retain the last 1000 messages in each category as test data sets, and the remaining messages will be used as training data sets.
Model We will use a simple model that can be quickly trained, bag-of-words LogisTIc Classifier. This is a two-layer neural network (input layer and output layer). We could have used more complex models, such as LSTM, but the topic of this article is not to filter spam. In addition, the word bag LR works very well on spam detection (surprisingly, it also performs well on many other tasks). ). So don't over-complicate. Below is the code to create this classifier. If you are not sure how it works, you can refer to my previous article on Numpy to implement neural networks: backpropagation.
(On my machine, the following code works on both Python 2 and Python 3.)
Import numpy as np
From collecTIons importCounter
Import random
Import sys
Np.random.seed(12345)
f = open('spam.txt','r')
Raw = f.readlines()
F.close()
Spam = list()
For row in raw:
Spam.append(row[:-2].split(" "))
f = open('ham.txt','r')
Raw = f.readlines()
F.close()
Ham = list()
For row in raw:
Ham.append(row[:-2].split(" "))
classLogisTIcRegression(object):
Def __init__(self, posiTIves, negatives, iterations=10, alpha=0.1):
#Create a glossary (real world case will add millions of other words
# and other words crawled from the web)
Cnts = Counter()
For email in (positives+negatives):
For word in email:
Cnts[word] += 1
# Convert to lookup table
Vocab = list(cnts.keys())
Self.word2index = {}
For i, word in enumerate(vocab):
Self.word2index[word] = i
# Initialize unencrypted weights
Self.weights = (np.random.rand(len(vocab)) - 0.5) * 0.1
# Train the model on unencrypted information
Self.train(positives,negatives,iterations=iterations,alpha=alpha)
Def train(self,positives,negatives,iterations=10,alpha=0.1):
For iter in range(iterations):
Error = 0
n = 0
For i in range(max(len(positives),len(negatives))):
Error += np.abs(self.learn(positives[i % len(positives)],1,alpha))
Error += np.abs(self.learn(negatives[i % len(negatives)],0,alpha))
n += 2
Print("Iter:" + str(iter) + " Loss:" + str(error / float(n)))
Def softmax(self,x):
Return1/(1+np.exp(-x))
Def predict(self,email):
Pred = 0
For word in email:
Pred += self.weights[self.word2index[word]]
Pred = self.softmax(pred)
Return pred
Def learn(self,email,target,alpha):
Pred = self.predict(email)
Delta = (pred - target)# * pred * (1 - pred)
For word in email:
Self.weights[self.word2index[word]] -= delta * alpha
Return delta
Model = LogisticRegression(spam[0:-1000],ham[0:-1000],iterations=3)
#Evaluate on the retention set
Fp = 0
Tn = 0
Tp = 0
Fn = 0
For i,h in enumerate(ham[-1000:]):
Pred = model.predict(h)
If(pred < 0.5):
Tn += 1
Else:
Fp += 1
If(i % 10 == 0):
Sys.stdout.write('I:'+str(tn+tp+fn+fp) + " % Correct:" + str(100*tn/float(tn+fp))[0:6])
For i,h in enumerate(spam[-1000:]):
Pred = model.predict(h)
If(pred >= 0.5):
Tp += 1
Else:
Fn += 1
If(i % 10 == 0):
Sys.stdout.write('I:'+str(tn+tp+fn+fp) + " % Correct:" + str(100*(tn+tp)/float(tn+tp+fn+fp))[ 0:6])
Sys.stdout.write('I:'+str(tn+tp+fn+fp) + " Correct: %" + str(100*(tn+tp)/float(tn+tp+fn+fp))[ 0:6])
Print("Test Accuracy: %" + str(100*(tn+tp)/float(tn+tp+fn+fp))[0:6])
Print("False Positives: %" + str(100*fp/float(tp+fp))[0:4] + " <- privacy violation level out of 100.0%")
Print("False Negatives: %" + str(100*fn/float(tn+fn))[0:4] + " <- security risk level out of 100.0%")
result:
Iter:0Loss:0.0455724486216
Iter: 1Loss: 0.0173317643148
Iter: 2Loss: 0.0113520767678
I:2000Correct: %99.798
TestAccuracy: %99.7
FalsePositives: %0.3 <- privacy violation level out of 100.0%
FalseNegatives: %0.3 <- security risk level out of 100.0%
Features: Auditability This classifier has a great feature, it is a highly auditable algorithm. Not only does it give an accurate score on the test data, we can also open it and see how it differs in the weight of the different words to ensure it is based on the spam required by Bob's chief. Based on these insights, Chief Bob can obtain permission from his superiors to perform extremely limited monitoring of clients within the jurisdiction. Note that Bob can't read anyone's mail, he can only detect the target he needs to detect.
Ok, our classifier got approval from Bob's superior (Sheriff?). In general, Bob will add this classifier to all mail clients in the jurisdiction. Each client uses a classifier to make predictions before sending a message. The forecast will be sent to Bob, and gradually, Bob will find out who sent 10,000 spam messages anonymously every day in his jurisdiction.
Question 1: The forecast can be forged. After a week, everyone still receives tons of spam. Bob's classifier doesn't seem to be able to mark any spam, although it works fine when tested on Bob's own machine. Bob suspects that someone has intercepted the algorithm's predictions, making spam look "negative." What should he do?
Problem 2: The model can be reverse engineered. In addition, Bob notices that he can get weight values ​​from the pre-trained model:
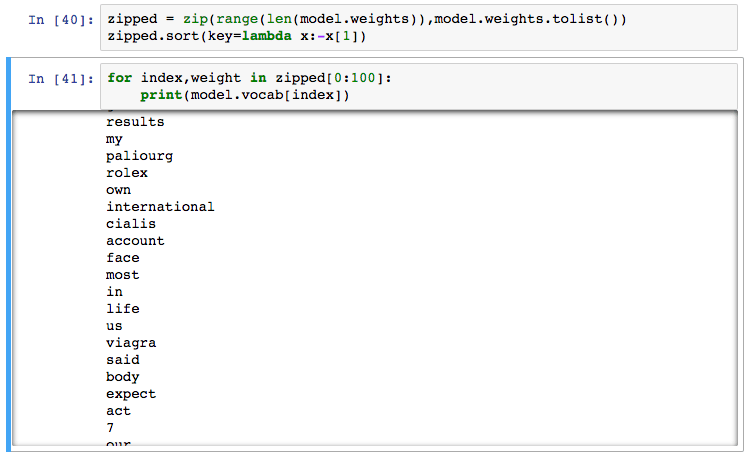
Although from an auditable point of view, this is an advantage (to let Bob's superiors be confident that the model will only find the information needed for the design purpose), it is easy to be attacked! People can not only intercept and modify the predictions of the model, but also reverse engineering systems to find out which words need to be avoided. In other words, the capabilities and predictions of the model are vulnerable. Bob needs an extra line of defense.
Five, homomorphic encryption
In a previous article, I outlined how to train a neural network with encrypted state using the homomorphic encryption (training data is not encrypted), and the algorithm implementation is based on efficient integer vector homomorphic encryption. However, the previous article mentioned that there are many homomorphic encryption schemes to choose from. This article will use a different scheme, Paillier Encryption. I updated the Paillier-encrypted Python library, added the ability to handle long-form ciphertext and plaintext, and modified a bug in the logging function.
You can install my modified Paillier library with the following command:
Git clone https://github.com/iamtrask/python-paillier.git
Cd python-paillier
Python setup.py install
Then run the following code:
Import phe as paillier
Pubkey, prikey = paillier.generate_paillier_keypair(n_length=64)
a = pubkey.encrypt(123)
b = pubkey.encrypt(-1)
Prikey.decrypt(a) # 123L
Prikey.decrypt(b) # -1L
Prikey.decrypt(a + a) # 246
Prikey.decrypt(a + b) # 122
As you can see, we can use the public key to encrypt (positive or negative) numbers, then add the encrypted values ​​and then decrypt the results. We use these operations to encrypt our trained logistic regression classifiers. If you want to know how these work, please refer to my previous article.
Import phe as paillier
Import math
Import numpy as np
From collections importCounter
Import random
Import sys
Np.random.seed(12345)
Print("Generating paillier keypair")
Pubkey, prikey = paillier.generate_paillier_keypair(n_length=64)
Print("Importing dataset from disk...")
f = open('spam.txt','r')
Raw = f.readlines()
F.close()
Spam = list()
For row in raw:
Spam.append(row[:-2].split(" "))
f = open('ham.txt','r')
Raw = f.readlines()
F.close()
Ham = list()
For row in raw:
Ham.append(row[:-2].split(" "))
classHomomorphicLogisticRegression(object):
Def __init__(self, positives, negatives, iterations=10, alpha=0.1):
Self.encrypted=False
Self.maxweight=10
#Create a glossary (real world case will add millions of other words
# and other words crawled from the web)
Cnts = Counter()
For email in (positives+negatives):
For word in email:
Cnts[word] += 1
# Convert to lookup table
Vocab = list(cnts.keys())
Self.word2index = {}
For i, word in enumerate(vocab):
Self.word2index[word] = i
# Initialize unencrypted weights
Self.weights = (np.random.rand(len(vocab)) - 0.5) * 0.1
# Train the model on unencrypted information
Self.train(positives,negatives,iterations=iterations,alpha=alpha)
Def train(self,positives,negatives,iterations=10,alpha=0.1):
For iter in range(iterations):
Error = 0
n = 0
For i in range(max(len(positives),len(negatives))):
Error += np.abs(self.learn(positives[i % len(positives)],1,alpha))
Error += np.abs(self.learn(negatives[i % len(negatives)],0,alpha))
n += 2
Print("Iter:" + str(iter) + " Loss:" + str(error / float(n)))
Def softmax(self,x):
Return1/(1+np.exp(-x))
Def encrypt(self,pubkey,scaling_factor=1000):
If(not self.encrypted):
Self.pubkey = pubkey
Self.scaling_factor = float(scaling_factor)
Self.encrypted_weights = list()
For weight in model.weights:
Self.encrypted_weights.append(self.pubkey.encrypt(\\
Int(min(weight,self.maxweight) * self.scaling_factor)))
Self.encrypted = True
Self.weights = None
Return self
Def predict(self,email):
If(self.encrypted):
Return self.encrypted_predict(email)
Else:
Return self.unencrypted_predict(email)
Def encrypted_predict(self,email):
Pred = self.pubkey.encrypt(0)
For word in email:
Pred += self.encrypted_weights[self.word2index[word]]
Return pred
Def unencrypted_predict(self,email):
Pred = 0
For word in email:
Pred += self.weights[self.word2index[word]]
Pred = self.softmax(pred)
Return pred
Def learn(self,email,target,alpha):
Pred = self.predict(email)
Delta = (pred - target)# * pred * (1 - pred)
For word in email:
Self.weights[self.word2index[word]] -= delta * alpha
Return delta
Model = HomomorphicLogisticRegression(spam[0:-1000],ham[0:-1000],iterations=10)
Encrypted_model = model.encrypt(pubkey)
# Generate an encrypted prediction. Then decrypt them and evaluate them.
Fp = 0
Tn = 0
Tp = 0
Fn = 0
For i,h in enumerate(ham[-1000:]):
Encrypted_pred = encrypted_model.predict(h)
Try:
Pred = prikey.decrypt(encrypted_pred) / encrypted_model.scaling_factor
If(pred < 0):
Tn += 1
Else:
Fp += 1
Except:
Print("overflow")
If(i % 10 == 0):
Sys.stdout.write(' I:'+str(tn+tp+fn+fp) + " % Correct:" + str(100*tn/float(tn+fp))[0:6])
For i,h in enumerate(spam[-1000:]):
Encrypted_pred = encrypted_model.predict(h)
Try:
Pred = prikey.decrypt(encrypted_pred) / encrypted_model.scaling_factor
If(pred > 0):
Tp += 1
Else:
Fn += 1
Except:
Print("overflow")
If(i % 10 == 0):
Sys.stdout.write(' I:'+str(tn+tp+fn+fp) + " % Correct:" + str(100*(tn+tp)/float(tn+tp+fn+fp))[ 0:6])
Sys.stdout.write(' I:'+str(tn+tp+fn+fp) + " % Correct:" + str(100*(tn+tp)/float(tn+tp+fn+fp))[ 0:6])
Print(" Encrypted Accuracy: %" + str(100*(tn+tp)/float(tn+tp+fn+fp))[0:6])
Print("False Positives: %" + str(100*fp/float(tp+fp))[0:4] + " <- privacy violation level")
Print("False Negatives: %" + str(100*fn/float(tn+fn))[0:4] + " <- security risk level")
Output:
Generating paillier keypair
Importing dataset from disk...
Iter:0Loss:0.0455724486216
Iter: 1Loss: 0.0173317643148
Iter: 2Loss: 0.0113520767678
Iter: 3Loss: 0.00455875940625
Iter: 4Loss: 0.00178564065045
Iter: 5Loss: 0.000854385076612
Iter: 6Loss: 0.000417669805378
Iter: 7Loss: 0.000298985174998
Iter: 8Loss: 0.000244521525096
Iter: 9Loss: 0.000211014087681
I: 2000 % Correct: 99.296
EncryptedAccuracy: %99.2
FalsePositives: %0.0 <- privacy violation level
FalseNegatives: %1.57 <- security risk level
This model is quite special (and very fast!... on my laptop, running in a single thread, can process about 1000 messages per second). Note that we did not use sigmoid in the prediction (only sigmoid was used during training) because the threshold is 0.5. Therefore, we can simply skip sigmoid and set the threshold to 0 after the test. Ok, I have already talked about enough technical aspects, let's go back to Bob.
The problem Bob had before was that people could see predictions and fake predictions. However, all predictions are now encrypted.

In addition, Bob also encountered problems with people reading weights and reverse engineering. However, the weight of ownership is now encrypted (and can be predicted in encrypted state)!
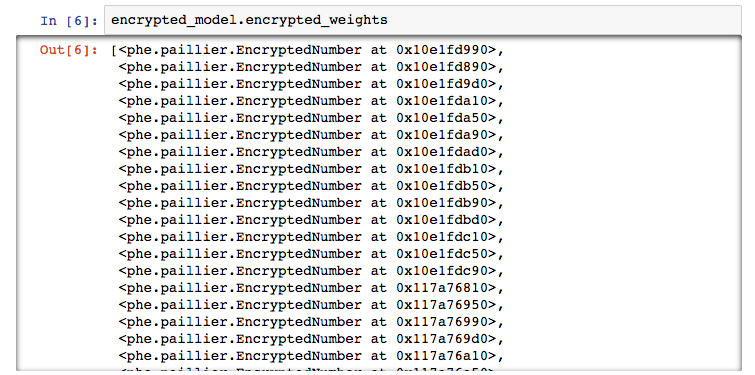
This model has many of the properties we want. It can be audited by a third party, and the prediction is encrypted. For those who want to steal/follow the system, its intelligence is also encrypted. Other than that, it's quite accurate (no false positives on the test data set) and it's fast.
Sixth, create a security crime test
Let us consider what this model means for law enforcement. Today, in order to anticipate incidents such as murder and terrorist attacks, law enforcement agencies need unrestricted access to data streams. Therefore, in order to detect events with a probability of 0.0001% in the data, law enforcement needs to access 100% of the data and transfer the data to a secret data warehouse. (I assume) the machine learning model is deployed in the data warehouse.
However, these machine learning models, now used to identify crime, can actually encrypt themselves and be deployed on data streams (for example, chat applications). Law enforcement only accesses the predictions of the model, rather than accessing the entire data set. This is similar to the drug dog in the airport. The drug dog eliminated the need for law enforcement to search each person's luggage for cocaine. Instead, dogs can detect the presence of drugs exclusively through training (like a machine learning model). Call == There is a drug. Not called == No drugs. A positive neural network prediction means “planning a terrorist activity on this phoneâ€, and a negative neural network prediction means “not planning terrorist activities on this phoneâ€. Law enforcement does not need to see the data. They only need this one data point. In addition, since the model is decentralized intelligence, it can be independently evaluated to ensure that it only detects what needs to be detected (as we can assess the accuracy of the drug dog in the test to independently audit what the dog is used to train). However, unlike drug dogs, encrypted artificial intelligence can provide the ability to detect any crime that can be detected by electronic evidence.
Audit considerations So, who should we trust to audit? I am not a political science expert, so I will leave this question to others. However, I believe that third-party monitors, government employees, and even open source software developers can take on this role. If there are enough versions of each type of detector, it can be difficult for a malicious user to find out which version is being deployed (because they are encrypted). I think there are many viable options here, and the issue of auditing entities has been discussed by many people, so I will leave this part to the experts.
Ethical considerations Literary works have many comments on the ethical and moral implications of crime predictions that lead to direct convictions (such as the Minority Report). However, the main value of crime prediction is not the efficient punishment and imprisonment, but the prevention of harm. Therefore, there are two trivial ways to prevent this ethical dilemma. First, most major crimes require some lighter crimes to prepare, and many moral dilemmas can be avoided by more accurately detecting lighter crimes and predicting major crimes. Second, crime prevention techniques can be used to optimize police resource allocation and trigger search/survey methods. A positive prediction should lead to an investigation rather than directly putting people into jail.
Legal Considerations The United States v. Place case ruled that the use of a drug dog is not considered a “search†because the drug dog can exclusively detect the smell of the drug (without detecting other things). In other words, because they can classify crimes without requiring residents to disclose other information, it is not considered a violation of privacy. In addition, I believe that the general view of the public and the law are consistent. At the airport, a furry dog ​​comes to sniff your bag quickly and is a very efficient form of privacy protection. It’s strange to say that dogs can definitely train to detect any embarrassing things in your bag. However, it only trains to detect signs of crime. Similarly, agents can train to detect only signs of crime without detecting anything else. Therefore, the model with sufficient accuracy should have a legal status comparable to that of a drug dog.
Corruption considerations Perhaps you want to ask: “Why is innovation in this area? Why is there a new monitoring method? Are we not monitoring enough?†My answer is: companies or governments should be unable to monitor anyone who does not harm others ( innocent). Instead, we want to detect anyone who is about to hurt others to stop them. Before the recent technological advances, the two could not be achieved at the same time. This article wants to argue: I believe that it is feasible to guarantee security and privacy while technically. I mean, privacy doesn't depend on the authorities' whimsy, but on auditable technologies like encrypted artificial intelligence. Who is responsible for auditing this technology without revealing it to malicious people? I am not sure. Maybe a third-party inspection agency. Perhaps this would be a system that people can choose to join (like a smoke alarm), and then use social contracts to get people to avoid people who don't join. Maybe it's developed entirely in open source, but it's efficient enough to be bypassed? This is a question worthy of further discussion. This article is not a complete solution. Social structures and government structures undoubtedly require adjustments for such tools. However, I believe this is a goal worth pursuing, and I look forward to the discussion that has arisen in this article.
Seven, future work
First and foremost, we need modern floating-point vector homomorphic encryption algorithms (FV, YASHE, etc.) supported by the mainstream deep learning framework (PyTorch, TensorFlow, Keras, etc.). Second, exploring how to increase the speed and security of these algorithms is a highly innovative and extremely important task. Finally, we need to imagine how social structures can work with these new tools to protect people's safety without invading privacy (and continue to reduce the risk of abuse of the technology by the authorities).
Antenk DVI Series Digital Video Interface connectors are the standard digital interface for flat panels, video graphics cards, monitors and HDTV units. This series includes DVI-D (Digital), DVI-A (Analog) and DVI-I (Integrated Digital/Audio). Their unique crossing ground blades provide high speed performance at low cost. They are available in Straight or Right Angle PCB mount receptacles and mating male cable connectors. They support a data transfer rate of 4.95Gbps with a dielectric withstanding voltage of 500VAC. Each version features our specially designed contacts which improve signal performance and a zinc alloy shield that reduces electromagnetic interference (EMI).
Digital Visual Interface Cable Connectors
DVI ConnectorWith the advent of technologies such as DVD players, high-definition televisions, and even digital cable, the need for more advanced cables and connectors has increased. Digital Visual Interface (DVI) is one response to the growing need for interconnected systems, enabling digital systems to be connected to an array of displays. Yet DVI cables and connectors can also be complicated, and may lead to confusion between High Definition Multimedia Interface (HDMI) and DVI. Although the two systems have much in common, they service different niches of digital technology.
Digital Visual Interface
Older systems aren`t necessarily outdated systems. Although DVI preceded HDMI, it`s still widely used in both business and domestic settings. DVI connectors are designed to handle digital data transmission, incorporating three transmission channels in every connector link. The maximum bandwidth for data transfer is 165 megahertz, which is enough to relay up to 165 million pixels per second. Data is encoded for effective transfer, but a single link can handle around 4.95 gigabits per second of information. Double links can handle twice that amount.
Because a DVI cable carries information over a 165 megahertz bandwidth, complete digital resolution can be obtained. Using double link connectors increases the speed of transmission, but requires another cable. However, not many devices depend solely on a double link DVI, so this technolgy can be used on an as-desired basis.
Types of DVI Connectors
There are three general categories of DVI cable connectors: DVI-Digital (DVI-D), DVI-Integrated (DVI-I), and DVI-Analog (DVI-A). However, most connectors fall into one of the first two groups.
A standard DVI Connector is 37 mm wide and has 24 pins, 12 of which are used for a single link connection. When analog is involved, four additional pins are needed to support the additional lines of an analog signal. It is not possible to cross from a digital source to an analog display or vice versa. In those instances, an integrated connector is probably the best option. There are five common types of DVI connectors.
DVI-I Single Link
This kind of connector has three rows, each with six pins. There are two contacts. Because the connector is integrated, it can be used with both analog and digital applications.
DVI-I Dual Link
A DVI-I dual link connector can also be used with both digital and analog applications, but is configured with more pins to accommodate a dual connection. There are three rows with eight pins each, as well as two contacts.
DVI-D Single Link
Specifically designed for digital applications, a DVI-D single link connector has three rows of six pins, and looks much like a DVI-I single link connector. However, a DVI-D connector has no contacts.
DVI-D Dual Link
Also made specifically for digital applications, a DVI-D dual link features more pins (three rows of eight) for dual connections. Like a DVI-D single link, a DVI-D dual link connector has no contacts.
DVI-A
This particular type of connector can only be used for analog applications, and has three rows of pins. One row has five pins, one has four pins, and the last row has three pins. Like single link connectors, a DVI-A link connector has two contacts.
Female DVI Connector
ShenZhen Antenk Electronics Co,Ltd , https://www.antenkelec.com