Researchers at MIT CSAIL found that ResNet with only one neuron in the hidden layer is a general function approximator, and identity mapping does strengthen the expressive ability of deep networks. The researchers said that this discovery also fills a theoretical gap in the reason for the strong expressive power of fully connected networks.
Deep neural networks are the key to the success of many current machine learning applications, and a major trend of deep learning is that neural networks are getting deeper and deeper: take computer vision applications as an example, from the very beginning AlexNet to the later VGG-Net, and then Up to the recent ResNet, the performance of the network has indeed improved as the number of layers increases.
An intuitive feeling of researchers is that as the depth of the network increases, the capacity of the network becomes higher and it is easier to approximate a certain function.
Therefore, from the theoretical point of view, more and more people are beginning to care about whether all functions can be approximated by a sufficiently large neural network?
In a paper recently uploaded to Arxiv, two researchers from MIT CSAIL started with the ResNet structure to demonstrate this problem. They found that ResNet with only one neuron in each hidden layer is a general approximation function. This holds true regardless of the depth of the entire network, even if it tends to infinity.

One neuron is enough. Isn’t that exciting?
Understand the general approximation theorem in depth
There has been a lot of discussion about the representational power of neural networks.
Some studies in the 1980s found that as long as there are enough hidden layer neurons, a neural network with a single hidden layer can approximate any continuous function with arbitrary accuracy. This is also known as the universal approximation theorem.
However, this is understood from the perspective of "width" rather than "depth"-increasing the number of hidden layer neurons, increasing the width of the network-and actual experience tells us that deep networks are the most suitable for learning The function of solving real-world problems.
Therefore, this naturally leads to a question:
If the number of neurons in each layer is fixed, will the general approximation theorem still hold when the network depth increases to infinity?
The article "The Expressive Power of Neural Networks: A View from the Width" published by Zhou Lu of Peking University and others in NIPS 2017 found that for a fully connected neural network that uses ReLU as the activation function, when each hidden layer has at least d+4 The general approximation theorem holds when there are d neurons (d represents the input space), but it does not hold when there are at most d neurons.
So, with another structure, will this condition still hold? What exactly affects the expressive power of deep networks?
The two researchers at MIT CSAIL thought of ResNet.
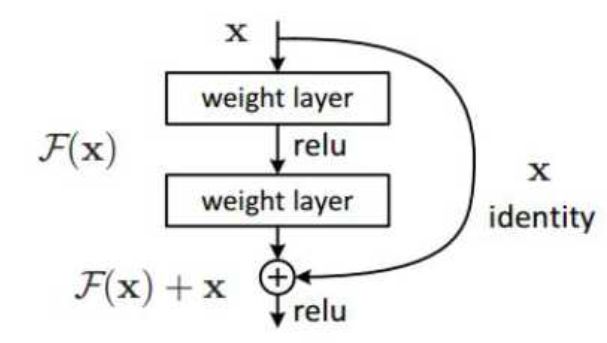
Since He Yuming and others proposed it in 2015, ResNet has even been considered as the current best-performing network structure. The success of ResNet is due to the introduction of shortcut connections and the identity mapping based on this, so that data flows can flow across layers. The original problem is transformed to make the residual function (F(x)=H(x)-x) approach 0, instead of directly fitting an identity function H'(x).
Due to the identity mapping, the width of ResNet is equal to the input space. Therefore, the author constructed such a structure and kept shrinking the hidden layer to see where the limit is:
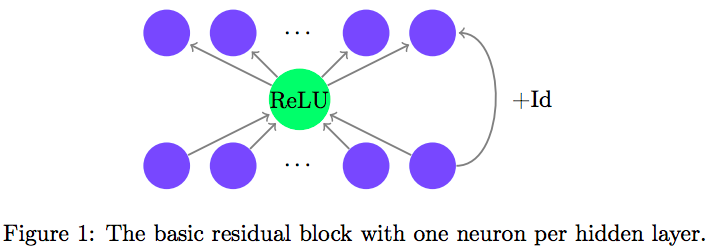
As a result, as mentioned above, at least one neuron is enough.
The author said that this further shows theoretically that the identity mapping of ResNet does enhance the expressive ability of deep networks.

Example: the difference between a fully connected network and ResNet
The author gives a toy example of this: We first use a simple example to empirically explore the difference between a fully connected network and ResNet, where each hidden layer of the fully connected network has d neurons. An example is: classifying unit balls in a plane.
Randomly generated samples for training set 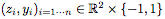 Composition, where
Composition, where
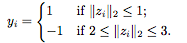
We artificially created a boundary between positive and negative samples to make the classification task easier. We use logical loss as loss 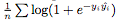 ,among them
,among them  Is the output of the network at the i-th sample. After training, we describe the decision boundary of various deep network learning. Ideally, we want the decision boundary of the model to be close to the true distribution.
Is the output of the network at the i-th sample. After training, we describe the decision boundary of various deep network learning. Ideally, we want the decision boundary of the model to be close to the true distribution.

Figure 2: In the unit ball classification problem, the decision boundary obtained by training a fully connected network with a width d = 2 in each hidden layer (top row) and a ResNet with only one neuron in each hidden layer (bottom row). Fully connected networks cannot capture real functions, which is consistent with the theory that the width d is too narrow for general approximation. On the contrary, ResNet approximates the function very well and supports our theoretical results.
Figure 2 shows the result. For a fully connected network (top row), the learned decision boundary has roughly the same shape for different depths: the quality of the approximation does not seem to improve with increasing depth. Although people may be inclined to think that this is caused by local optimality, our results are consistent with the results in [19]:
Proposition 2.1. Let 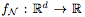 Is a function defined by a fully connected network N with ReLU activation. use
Is a function defined by a fully connected network N with ReLU activation. use 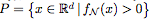 Means
Means 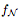 The set of positive levels. If each hidden layer of N has at most d neurons, then
The set of positive levels. If each hidden layer of N has at most d neurons, then
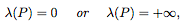 , Where λ means Lebesgue measure
, Where λ means Lebesgue measure
In other words, the level set of "narrow" fully connected networks is unbounded or has a zero measure.
Therefore, even when the depth tends to infinity, the "narrow" fully connected network cannot approach the bounded area. Here we only show the case of d=2, because the data can be seen easily; the same observations can be seen in higher dimensions.
The decision boundary of ResNet looks obviously different: although the width is narrower, ResNet represents an indicator of a bounded area. As the depth increases, the decision boundary seems to tend to the unit ball, which means that Proposition 2.1 cannot be applied to ResNet. These observations inspired the general approximation theorem.
discuss
In this article, we show the general approximation theorem for the ResNet structure with only one neuron in each hidden layer. This result is in contrast to recent results on fully connected networks, for which the universal approximation will fail when the width is d or less.
ResNet vs Fully Connected Network:
Although we use only one hidden neuron in each basic residual block to achieve a general approximation, one might say that the structure of ResNet still passes the identity to the next layer. This identity map can be counted as d hidden units, resulting in a total of d+1 hidden units for each residual block, and the network is regarded as a fully connected network with a width of (d + 1). However, even from this perspective, ResNet is equivalent to a compressed or sparse version of a fully connected network. In particular, a fully connected network of width (d + 1) has each layer 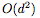 Connections, and ResNet only
Connections, and ResNet only  A connection, thanks to the identity map. This "over-parameterization" of fully connected networks may explain why dropout is useful for such networks.
A connection, thanks to the identity map. This "over-parameterization" of fully connected networks may explain why dropout is useful for such networks.
In the same way, our results show that a fully connected network of width (d + 1) is a universal approximator, which is a new discovery. The structure in [19] requires d + 4 units per layer, leaving a gap between the upper and lower boundaries. Therefore, our results close the gap: a fully connected network of width (d + 1) is a universal approximator, while a fully connected network of width d is not.
Why is universal approximation important? As we stated in Section 2 of the paper, a fully connected network of width d can never approach a compact decision boundary, even if we allow infinite depth. However, in a high-dimensional space, it is difficult to visualize and inspect the obtained decision boundary. The general approximation theorem provides a completeness check and ensures that in principle we can capture any desired decision boundary.
Training efficiency:
The general approximation theorem only guarantees the possibility of approximating any desired function, but it does not guarantee that we can actually find it by running SGD or any other optimization algorithm. Understanding training efficiency may require a better understanding of optimization scenarios, which is a topic that has received attention recently.
Here, we are trying to put forward a slightly different perspective. According to our theory, ResNet with one-neuron hidden layers is already a general approximator. In other words, ResNet with multiple units in each layer is in a sense over-parameterization of the model, and over-parameterization has been observed to be beneficial to optimization. This may be one of the reasons why training a very deep ResNet is "easier" than training a fully connected network. Future work can analyze this more rigorously.
Generalization:
Since a general approximator can fit any function, one might think that it is easy to overfit. However, it can usually be observed that the generalization effect of deep networks on the test set is very good. The explanation of this phenomenon is irrelevant to our paper, but understanding the general approximation ability is an important part of this theory. In addition, our results suggest that the aforementioned "over-parameterization" may also play a role.
to sum up:
In summary, we give a general approximation theorem for ResNet with a single neuron hidden layer. This theoretically distinguishes ResNet from fully connected networks, and our results fill the gap in understanding the representation capabilities of fully connected networks. To a certain extent, our results theoretically motivated deeper practice of the ResNet architecture.
If you are tired of the original back of your phone, you should try our 3D Relief Back Sticker. The Back Skin Protective Film on the back can not only bring you a visual change, but also protect the back cover of the phone itself from scratches and collisions. Real 3D touch, personalized and stylish pattern design. Bring you a perfect experience.
In daily use, it can protect the equipment from scratches, dust, impact and other damage.
Long-lasting anti-scratch effect, significantly reducing dust, oil stains and fingerprint stains.
Easy to install, easy to stick to the back of the phone, and will not damage the original appearance of the phone.
With the Protective Film Cutting Machine, you can install the Back Film on different types of mobile phone back shells, including mobile phones, tablet computers and other electronic products. Customization can be completed in 30 seconds with just one click.
If you want to know more about 3D Relief Back Sticker, please click product details to view the parameters, models, pictures, prices and other information about 3D Relief Back Sticker.
Whether you are a group or an individual, we will try our best to provide you with accurate and comprehensive information about 3D Relief Back Sticker!
3D Phone Sticker, Carbon Fiber Back Sticker, 3D Relief Back Sticker, 3D Printing Back Sticker, Phone Skin,Mobile Phone Back Sticker
Shenzhen Jianjiantong Technology Co., Ltd. , https://www.hydrogelprotectivefilm.com