More and more applications involve big data, and unfortunately all the attributes of big data, including quantity, speed, diversity, etc., describe the growing complexity of the database. So what benefits does big data bring to us? The biggest benefit of big data is that it allows us to analyze a lot of intelligent, in-depth and valuable information from these data.
Recently, we compared the performance of 179 different classification learning methods (classification learning algorithms) on 121 data sets, and found that Random Forest and SVM have the highest classification accuracy, in most cases more than others. method. This article is aimed at "How many tools do you need for big data analysis?"
Classification methodBig data analysis relies mainly on machine learning and large-scale computing. Machine learning includes supervised learning, unsupervised learning, and intensive learning. Supervised learning includes classification learning, regression learning, sorting learning, and matching learning (see Figure 1). Classification is the most common machine learning application problem, such as spam filtering, face detection, user portraits, text sentiment analysis, web page categorization, etc., which are essentially classification issues. Classification learning is also the most thoroughly studied and widely used branch of the field of machine learning.
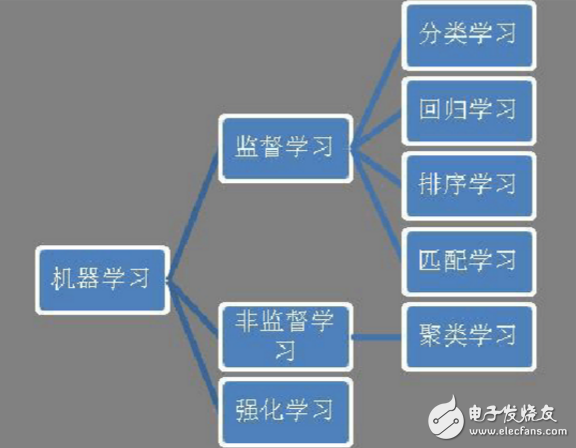
Figure 1 Machine learning classification system
Recently, Fernández-Delgado et al. published an interesting paper in the JMLR (Journal of Machine Learning Research) magazine. They asked 179 different classification learning methods (classification learning algorithms) to perform "big contests" on UCI's 121 data sets (UCI is a machine learning public data set, each of which is small in size). It was found that Random Forest and SVM (support vector machine) ranked first and second, but the difference between the two was small. On 84.3% of the data, Random Forest overwhelmed the other 90% of the methods. That is to say, in most cases, only using Random Forest or SVM things will be done.
Summary of some experiencesHow many machine learning methods do you need for big data analysis? Around this issue, let's take a look at some of the empirical rules that have been developed in the field of machine learning for many years.
The performance of big data analysis is good, that is to say, the accuracy of machine learning prediction is related to the learning algorithm used, the nature of the problem, the characteristics of the data set, including the data size and data characteristics.
In general, the Ensemble method includes Random Forest and AdaBoost, SVM, and LogisTIc Regression with the highest classification accuracy.
There is no way to “package the worldâ€. Random Forest, SVM and other methods generally have the best performance, but not under what conditions the performance is the best.
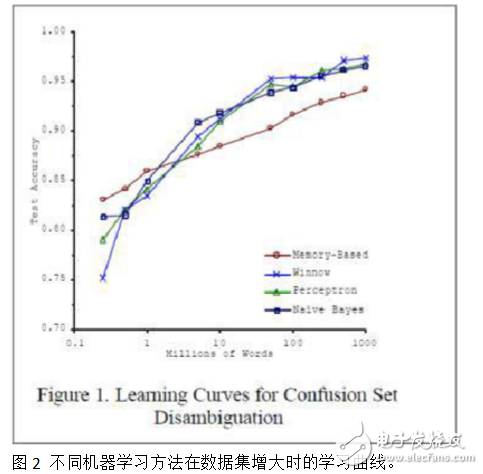
Different methods, when the data size is small, the performance tends to be quite different, but when the data size increases, the performance will gradually increase and the difference will gradually decrease. In other words, under the conditions of big data, what methods can work well. See the experimental results of Blaco & Brill in Figure 2.
For simple problems, methods such as Random Forest and SVM are basically feasible, but for complex problems such as speech recognition and image recognition, the recent popular deep learning methods tend to be better. The essence of deep learning is the study of complex models, which is the focus of future research.
In practical applications, to improve the accuracy of classification, it is more important to select features than the selection algorithm. Good features lead to better classification results, and the extraction of good features requires a deep understanding of the problem.
Stator Core assembly as a important process, there are kinds of technologies to assemble the stator core. Different sizes of stator cores have different technological processes and application fields. For example, small-sized stator cores are usually assembled by interlocking, and the outer diameter is usually less than 200mm. Large-sized stators are assembled in different ways depending on the motor design, such as stator core by cleating and staor core by welding. We are able to process all methods for stator core assembly based on customers' requirements.
Stator Core By Cleating,Splint Stator Core,Generator Stator Core,Stator Core Of Induction Motor
Henan Yongrong Power Technology Co., Ltd , https://www.hnyongrongglobal.com